导读:本文将介绍一个智能项目,我们将使用回归建模方式来模拟Capital Bikeshare系统中的自行车共享数据集,并了解温度、风和时间等变量是如何影响自行车租赁需求的。
作者:曼纽尔·阿米纳特吉(Manuel Amunategui)、迈赫迪·洛佩伊(Mehdi Roopaei)
如需转载请联系华章科技

加州大学尔湾分校的UCI机器学习库慷慨贡献了本文所需的数据集:
https://archive.ics.uci.edu/ml/datasets/bike+sharing+dataset
在进行本文实验前,请访问UCI网站下载相关数据集。
提示:
请访问
www.apress.com/9781484238721
单击“Download source code”按钮,跳转至GitHub网站,下载本文所需文件。推荐使用Jupyter Notebook打开chapter2.ipynb文件,以配合阅读本文内容。
01 共享单车租赁需求回归系数分析本文中,我们将构建一个简单直观的模型,并使其与不同的环境因素进行交互,进而了解这些环境因素是如何影响自行车租赁需求的。对用户来说,这会是一种很好的方式,因为这种方式可以让他们确认关于什么会让他们的用户租赁或不租赁自行车的直观判断。
当然,在有些情况下,他们也会感到很惊讶(比如,冬天骑车的人居然会比夏天还多——本文中,我们将让你亲眼看到这个现象)。
这个Web应用背后的“大脑”是一个线性回归模型(linear regression model)。它能够发现历史数据集与模型输出结果之间的线性关系。利用这个原理,通过线性回归模型,我们就可推断随着时间推移和不同环境参数的变化,自行车租赁在需求上的变化。最终我们希望看到的是,这个模型能否帮助我们预测未来的自行车租赁需求。
记住一点,无论何时,只要你打算将一个Python模型扩展到Web应用,那么在添加任何构建Web应用程序所需的额外层之前,必须解决该模型中当前的所有问题和缺陷(bug)。在将任何应用或内容移至云端前,请先把所有简单问题解决掉!遵循这条建议,后续会减少你很多不必要的麻烦。
02 探索共享单车原始数据集虽然是一种兴起不久的服务,共享单车已经受到极大欢迎。根据人工智能与决策支持实验室的Hadi Fanaee-T的说法(来自UCI机器学习数据集信息库讲义笔记):
与公共汽车或地铁等其他交通服务相反,共享单车模式中,骑行时长、出发和到达位置在系统中都被明确记录。这一功能将自行车共享系统变成了虚拟传感器网络,利用这个网络,可以感知到一个城市的移动性。因此,通过监测这些数据,城市中发生的很多重要事件都有希望被监控到。
下载的数据集包括两部分:hour.csv和day.csv,特征细节描述如下:
instant:记录索引dteday:日期season:季节(1:春 2:夏 3:秋 4:冬)yr:年份(0:2011,1:2012)mnth:月份(1~12)hr:小时(0~23)holiday:是否是假期weekday:工作日workingday:如果既不是周末也不是假期则值为1,否则为0weathersit:1. 晴朗,云层很少,部分多云2. 薄雾+多云,薄雾+短暂云,薄雾+少云,薄雾3. 小雪,小雨+雷雨+散云,小雨+散云4. 大雨+冰粒+雷暴+薄雾,雪+雾temp:标准化温度(摄氏度)计算公式:(t-t_min)/(t_max-t_min), t_min = -8, t_max = +39(仅在小时范围内)atemp:标准化体表温度(摄氏度)计算公式:(t-t_min)/(t_max-t_min), t_min = -16, t_max = +50 (仅在小时范围内)hum:归一化湿度。值除以100(最大值)windspeed:归一化风速。值除以67(最大值)casual:临时用户数registered:注册用户数cnt:租赁自行车总数,包括临时用户和注册用户1. 下载UCI机器学习库数据集
你可以使用Python命令行或者手工方式,从UCI的机器学习数据仓库中直接下载数据集。数据集下载地址为:
https://archive.ics.uci.edu/ml/datasets/bike+sharing+dataset
下载到的数据中包含三个文件:
day.csvhour.csvReadme.txt在自行车租赁数据中,日数据集day.csv有731行,小时数据集hour.csv有17 379个记录。
2. Jupyter Notebook配置使用
在开始使用本文的记事本文件前,我们首先来回顾一些基础知识。从GitHub上下载源代码文件后,打开终端窗口,然后进入chapter2目录。在这个目录中,你将看到两个文件和一个文件夹,如图2所示。

▲图2 终端窗口
requirements_jupyter.txt文件中包含了运行本文Jupyter记事本文件所需的Python库。通过运行“pip3”命令,你可以快速安装依赖库文件(代码清单①)。
代码清单① 安装运行Notebook所需的文件$ pip3 install -r requirements_jupyter.txt图2中,chapter2.ipynb文件就是本文的Jupyter Notebook文件。Jupyter Notebook文件的打开方式很多,最流行的是使用“jupyter notebook”命令(代码清单②)。如果在打开过程中出现问题,请参考Jupyter的官方文档。
代码清单② 启动Jupyter Notebook$ jupyter notebook此命令将会打开一个浏览器窗口,浏览器中会显示默认路径下的全部文件列表,单击chapter2.ipynb文件超链接,如图3所示。
▲图3 Jupyter浏览器界面显示的本文文件
然后,浏览器将打开一个新的Tab窗口和相应的Notebook界面,其中包含了与本文内容相关的全部探索实验代码。本书全部代码都基于Python 3.x编写。如果你使用其他Python版本,则需要调整部分代码片段。
在打开的Notebook界面上,单击第一个代码框使其高亮,然后单击上方的运行按钮,如图4所示。如果在执行过程中出现错误,则在继续之前请先解决当前错误,因为Jupyter Notebook中每个代码片段的执行都要依赖之前的执行结果(错误可能与Python的版本兼容性有关,或者缺失了必须安装的依赖库文件)。

▲图4 Jupyter Notebook代码框高亮显示并准备执行代码
Jupyter Notebook代码中都提供了使用Python命令行直接下载数据集的方式(如果存在防火墙问题,则需要手动下载)。
3. 数据集探索
Python Pandas库中的head()函数提供了查看数据集中前面几行的功能,如代码清单③和图5所示。
代码清单③ 查看数据集前面几行bikes_hour_df_raw.head()执行上述命令后,将看到图5中所示的结果。

▲图5 bike_df.head()输出结果
使用head()函数,我们会看到数据集中有日期格式、整数格式和浮点数格式的数据。另外,还能看到一些冗余的特征,如date(dteday)已经通过season、yr、mnth、hr等进行了分类。因此,数据集的dteday特征是可以抛弃不用的(虽然我们会暂时保留它以满足对数据集的探索需求)。
其他一些特征似乎是多余的,如temp和atemp,这可能需要进一步检查核实。我们还删除了casual和registered特征,因为这些特征无法帮助我们从单个用户的角度来模拟需求,而这正是我们要实现的Web应用程序重点。
根据季节、天气等因素预测用户注册数量,这可能会得到一个有趣的预测结果,但是这不符合我们当前的需求范围,因此我们将放弃这些特征。
本文中,我们仅保留真正需要的数据特征,这可以为我们后续分析消除数据混乱,并让我们的分析过程变得更清晰和易于理解,从而更好地实现我们数据科学和Web应用程序的目标。
代码清单④ 针对我们的目标,删除不必要的数据特征bikes_hour_df = bikes_hour_df_raw.drop(['casual', 'registered'], axis=1)Pandas Python库中的info()函数也是查看数据集所包含的数据类型、数量和空值的好方法(代码清单⑤)。
代码清单⑤ 查看数据特征信息输入:
bikes_hour_df.info()输出:
RangeIndex: 17379 entries, 0 to 17378 Data columns (total 15 columns): instant 17379 non-null int64 dteday 17379 non-null object season 17379 non-null int64 yr 17379 non-null int64 mnth 17379 non-null int64 hr 17379 non-null int64 holiday 17379 non-null int64 weekday 17379 non-null int64 workingday 17379 non-null int64 weathersit 17379 non-null int64 temp 17379 non-null float64 atemp 17379 non-null float64 hum 17379 non-null float64 windspeed 17379 non-null float64 cnt 17379 non-null int64可以看到,使用info()函数,当前保存在内存中的所有数据都是浮点数或整数类型,并且它们都不是空值。如果我们碰巧有空值、日期数据类型或文本数据类型,则在继续建模之前,我们需要先解决这个问题。
就目前而言,大多数模型都需要数值类型数据,就如我们这里所拥有的一样,到目前为止我们的数据准备一切还算顺利!
4. 预测结果变量分析
接下来,我们将研究用以训练模型的结果变量cnt,即自行车租赁总数。Pandas库中的describe()函数是了解量化数据的另一种必备工具。此处,我们将它用于结果变量(也称为模型的标签),如代码清单⑥所示。
代码清单⑥ 查看自行车租赁cnt特征集概要信息输入:
bikes_hour_df['cnt'].describe()输出:
count 17379.000000 mean 189.463088 std 181.387599 min 1.000000 25% 40.000000 50% 142.000000 75% 281.000000 max 977.000000 Name: cnt, dtype: float64上述输出结果中,我们可以看到,cnt的值在最小值1和最大值977之间,也就是说在每一个有记录的小时内,自行车租赁数量最小是1辆,最多时是977辆,还可以看到,每小时平均自行车租赁数量是189.5辆。
另外,还可以确认我们所处理的是一个连续数值变量问题,因此,对于自行车租赁数量的训练和预测,线性回归(或者类似线性回归的模型)将是最佳选择。下面,我们将cnt数据绘制出来,以便更好地理解它,如代码清单⑦和图6所示。
代码清单⑦ 自行车租赁cnt特征集概要信息fig,ax = plt.subplots(1) ax.plot(sorted(bikes_hour_df['cnt']), color='blue') ax.set_xlabel(''Row Index'', fontsize=12) ax.set_ylabel(''Sorted Rental Counts'', fontsize=12) ax.set_ylabel(''Sorted Rental Counts'', fontsize=12) fig.suptitle('Outcome Variable - cnt - Rental Counts') plt.show()绘制结果如图6所示。

▲图6 自行车租赁数量排序结果显示,大部分租赁值在0~400范围内;高出部分属于稀有或异常值
5. 量化特征与租赁统计
接下来,我们将创建所有浮点类型数据的散点图。我们将基于租赁计数来进行绘制,以显示与租赁计数相关的潜在关系,如图7和图8所示。

▲图7 自行车被租赁数量与气温关系散点图(温度值已做归一化处理)
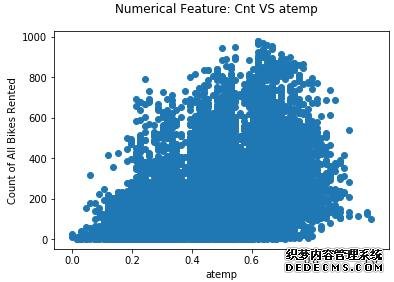
▲图8 自行车被租赁数量与体表温度关系散点图(温度值已做归一化处理)
可以看到,被租用的自行车数量和温度之间存在某种程度的线性关系;天气越温暖,租来的自行车越多。还可以看到,temp和atemp这两个特征具有相似的分布,并且可能出现冗余甚至多重共线性。为了保持单一线性,我们将删除atemp特征(在图9和图10中,仅有temp,而没有atemp特征)。

▲图9 自行车租赁数量与湿度关系散点图(湿度值已做归一化处理)

▲图10 自行车租赁数量与风速关系散点图(风速值已做归一化处理)
可以看到,特征hum或者湿度散点图中,所有数据点几乎都密集在一个范围内,尽管边缘处也出现了稀疏点。windspeed特征散点图中,风速与自行车租赁数量之间确实显示了非线性关系,风速越大,自行车租赁数量越少!
6. 分类特征研究
在我们已下载的数据集中,除了自行车租赁计数特征cnt外,其他的整数数据都具有分类特征。通过直方图查看时,分类数据会产生许多有趣的信息,如图11所示。

▲图11 依据season和weathersit分类的自行车租赁数量直方图
上图中可以看到,weathersit直方图表明好天气的时候,人们更喜欢租赁自行车;season直方图表明秋天是自行车租赁的高峰季节。
最后是特征hr或租赁时间直方图,清楚显示上班高峰时间和下午骑行时间段租赁自行车人数最多,而凌晨4点是最不受欢迎的骑行时间,如图12所示。

▲图12 按时间分类的自行车租赁数量直方图
尽管我们可以通过图表绘制方式来了解到很多东西,但是仍然需要进行更彻底和系统的检测,才能做出哪些特征需要保留,哪些特征需要抛弃的决策。
03 数据建模准备工作在大多数数据科学项目中,存在一个数据预处理阶段,在这个阶段会进行数据评估和清理,以实现数据的“模型就绪”。在清理阶段,我们已经放弃了一些无用的数据特征,同时也清除了可能存在的空值,我们也不用担心相关性或多重共线性,因为在最终模型中,我们仅会使用四个简单的特征。
1. 回归建模
在统计分析中,回归模型试图预测变量之间的关系。它主要用于分析独立变量与依赖变量的关系,而拟合模型(fitted model)则可用于预测依赖变量的新变化。
2. 简单线性回归
线性回归可能是最简单的建模算法。它试图解释一个因变量和一个或多个自变量之间的关系。基本的线性回归方程如图13所示。

▲图13 基本线性回归方程
在上述方程中,y是因变量,β0是常数,β1是回归系数,x是自变量。
3. 简单线性回归模型
这里,从一个简单的多线性回归模型开始,我们输入所有变量并获得均方根误差(RMSE)。RMSE最终转化到与结果变量(也称为y轴标签)相同的单位来表示误差(即RMSE值与y值具有相同量纲),因此很容易看出模型在学习/预测自行车租赁方面表现如何,而误差是置信区间的一种表现形式。
你所关注的是尽可能希望获得较低的RMSE值,因此我们的目标是不断调整数据和模型,直到RMSE值停止继续降低为止。本文中,我们所有建模工作都基于Python scitkit-learn /sklearn库。这是一个很了不起的Python库,几乎可以满足大多数Python用户的建模需求。
尽管我们只打算进行简单的线性回归,但我们还是用到了sklearn库中的三个函数:train_test_split函数从原始数据中创建两个随机数据集,并从结果中分离特征;linear_model函数运行我们的模型;mean_squared_error函数评估模型的学习效果(代码清单⑧)。
代码清单⑧ 将数据集拆分为训练和测试两部分的代码片段outcome = 'cnt' # create feature list features = [feat for feat in list(bike_df_model_ready) if feat not in [outcome, 'instant']] # split data into train and test portions from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(bike_df_model_ ready[features],bike_df_model_ready[['cnt']],test_size=0.3, random_state=42)train_test_split()函数基于用户指定的种子参数将原始数据集拆分为两个随机数据集。无论何时,如果想要测试不同的方法,并希望确保始终使用相同的拆分以进行不同方法的公平比较,则设置random_state种子参数是个不错的选择。
test_size参数设置测试拆分的大小,在这里我们将它设置为0.3或30%,因此最终结果将是数据集中70%的数据分配给了训练集,而剩余30%的数据分配给测试集(代码清单⑨)。
代码清单⑨ 线性回归代码from sklearn import linear_model model_lr = linear_model.LinearRegression() # train the model on training portion model_lr.fit(X_train, y_train)我们事先声明一个LinearRegression()模型,然后调用fit()函数,使用训练数据和训练标签来训练模型。执行上述代码后,模型model_lr即经过训练并准备好进行预测(代码清单⑩)。
代码清单⑩ 预测并获取均方根误差RMSE的代码输入:
predictions = model_lr.predict(X_test) from sklearn.metrics import mean_squared_error print(''Root Mean squared error: %.2f'' % sqrt(mean_squared_error(y_test,predictions)))输出:
Root Mean squared error: 143.08最后,我们调用函数predict(),并将分配为测试集的剩余30%数据传入函数,然后将预测标签值输入函数mean_squared_error()求取均方根误差值。我们最终得到的RMSE值为143.08,同时我们将其作为后续预测的基准参考值。
上述结果,也就是我们基于目前选择的数据特征和拆分种子值(我们在train_test_split函数上应用的种子,这可以确保我们每次都得到相同的数据分割)所得到的结果。
理解这个RMSE值的一种方式,就是我们的模型预测的偏差是143辆自行车(因为它与我们的结果变量处于相同的量纲)。考虑到每小时自行车平均租赁数量大约是190辆,因此,与简单采用自行车租赁的全局平均值相比,我们的模型做得更好。
我们能否通过几种技术手段(主要包括多项式、非线性建模和利用时间序列),获取更好的预测模型?由于篇幅有限,关于此问题的讨论请见《机器学习即服务》一书第2.4节。
关于作者:曼纽尔·阿米纳特吉(Manuel Amunategui) 是SpringML(谷歌云和Salesforce的优选合作伙伴)的数据科学副总裁,拥有预测分析和国际管理硕士学位。在机器学习、医疗健康建模等方面有着丰富的咨询经验。
迈赫迪·洛佩伊(Mehdi Roopaei)迈赫迪·洛佩伊(Mehdi Roopaei) 是IEEE、AIAA和ISA的高级成员。他的研究兴趣包括人工智能驱动的控制系统、数据驱动决策、机器学习和物联网(IoT),以及沉浸式分析。
本文摘编自《机器学习即服务:将Python机器学习创意快速转变为云端Web应用程序》,经出版方授权发布。

延伸阅读《机器学习即服务》
推荐语:本书涵盖Kubernetes架构、部署、核心资源类型、系统扩缩容、存储卷、网络插件与网络本书由浅入深地介绍了一系列常见的Python数据科学问题。通过本书,你将学习如何构建一个Web应用程序以进行数值或分类预测,如何理解文本分析,如何创建强大的交互界面,如何对数据访问进行安全控制,以及如何利用Web插件实现信用卡付款和捐赠。
 联通大数据:场景是金融大数据价值主秀场曹
联通大数据:场景是金融大数据价值主秀场曹 浙江绍兴:上虞“三色”预警通过国标验收
浙江绍兴:上虞“三色”预警通过国标验收